Understanding Large Language Models: A Comprehensive Guide to the Technology Reshaping Our World

By Roberto
In the rapidly evolving landscape of artificial intelligence, few technologies have captured public imagination and transformed industries as dramatically as Large Language Models (LLMs). From the viral success of ChatGPT to the integration of AI assistants in everyday applications, LLMs have moved from research laboratories to mainstream adoption in just a few short years. But what exactly are these powerful systems, how do they work, and what implications do they hold for our future?
Whether you're a business leader trying to understand the potential of AI for your organization, a student curious about the technology behind chatbots, or a technical professional seeking to deepen your knowledge, this comprehensive guide will take you through everything you need to know about Large Language Models. We'll explore their fundamental concepts, dive into the technology that makes them possible, examine the problems they solve, celebrate their advantages, and honestly discuss the challenges they present.
What Are Large Language Models?

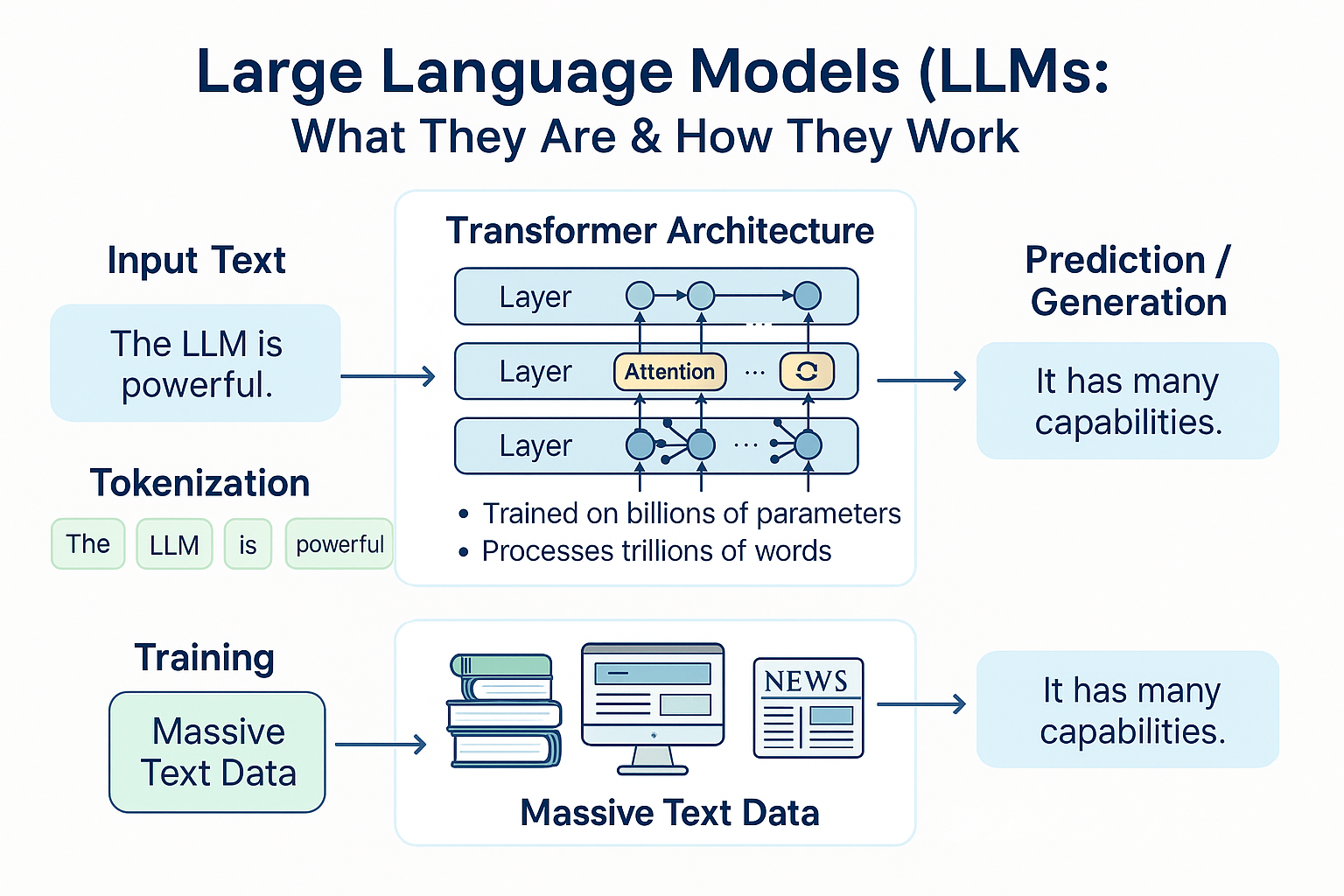
At its core, a Large Language Model is a type of artificial intelligence system trained on vast amounts of text data to understand, generate, and manipulate human language [1]. Think of it as an incredibly sophisticated pattern recognition system that has learned the intricate relationships between words, phrases, and concepts by analyzing billions of pages of text from books, websites, articles, and other written sources.
The term "large" in Large Language Model refers to two key aspects: the enormous amount of data these models are trained on, and the massive number of parameters (the internal settings that determine how the model processes information) they contain. Modern LLMs like GPT-4, Google's Gemini, or Anthropic's Claude contain hundreds of billions of parameters and have been trained on text datasets that would take a human thousands of lifetimes to read [2].
But LLMs are more than just sophisticated autocomplete systems. They represent a fundamental breakthrough in how machines can understand and generate human language. Unlike traditional software that follows explicit programming instructions, LLMs learn patterns and relationships from data, allowing them to perform tasks they were never explicitly programmed to do. This emergent capability is what makes them so powerful and, frankly, sometimes surprising even to their creators.
What Are Large Language Models (video)
The Foundation Model Revolution
LLMs belong to a category called foundation models – AI systems trained on broad data at scale that can be adapted to a wide range of downstream tasks [3]. This represents a significant shift from the traditional approach of building specialized AI systems for specific tasks. Instead of creating separate models for translation, summarization, question-answering, and content generation, a single LLM can potentially handle all these tasks and more.
This versatility stems from the models' ability to learn general patterns of language and reasoning during their training process. When you ask ChatGPT to write a poem, translate text, or explain a complex concept, you're witnessing the same underlying model applying its learned patterns to different types of tasks. It's like having a Swiss Army knife for language-related challenges.
The most prominent examples of LLMs that have captured public attention include OpenAI's GPT series (GPT-3, GPT-4, and the reasoning-focused GPT-o1), Google's BERT and more recent Gemini models, Anthropic's Claude, Meta's LLaMA models, and IBM's Granite series [4]. Each of these represents different approaches to the same fundamental challenge: creating machines that can understand and generate human language with remarkable fluency and accuracy.
The Problems LLMs Solve
The rise of Large Language Models addresses several longstanding challenges in computing and human-computer interaction. Understanding these problems helps explain why LLMs have generated such excitement across industries and applications.
Breaking Down Language Barriers
One of the most immediate and impactful applications of LLMs is in language translation and multilingual communication. Traditional translation systems relied on rule-based approaches or statistical methods that often produced awkward, literal translations that missed nuance and context. LLMs, having been trained on multilingual datasets, can provide more natural, contextually appropriate translations that capture not just the literal meaning but also the tone and intent of the original text [5].
This capability extends beyond simple translation to cross-cultural communication. LLMs can help adapt content for different cultural contexts, explain cultural references, and even adjust communication styles to be more appropriate for specific audiences. For global businesses, this represents a significant breakthrough in reaching diverse markets and customers.
Democratizing Content Creation
Content creation has traditionally been a time-intensive, skill-dependent process. Whether writing marketing copy, technical documentation, creative stories, or educational materials, producing high-quality written content required significant expertise and time investment. LLMs have dramatically lowered these barriers by serving as intelligent writing assistants that can help with everything from brainstorming ideas to polishing final drafts [6].
This democratization extends to various forms of content creation. LLMs can help generate blog posts, social media content, email campaigns, product descriptions, and even creative writing. They can adapt their writing style to match different audiences, from technical documentation for engineers to accessible explanations for general audiences. This capability has proven particularly valuable for small businesses and individuals who may not have access to professional writing resources.
Enhancing Customer Service and Support
Customer service has long been a challenge for businesses trying to balance cost, quality, and availability. Traditional chatbots were limited to scripted responses and simple decision trees, often frustrating customers with their inability to understand context or handle complex queries. LLMs have revolutionized this space by enabling chatbots and virtual assistants that can engage in natural, contextual conversations [7].
Modern LLM-powered customer service systems can understand complex queries, provide detailed explanations, handle follow-up questions, and even escalate issues appropriately to human agents when necessary. They can maintain context throughout a conversation, remember previous interactions, and provide personalized responses based on customer history and preferences.
Accelerating Research and Knowledge Discovery
Researchers and knowledge workers face an ever-growing challenge: the sheer volume of information available makes it increasingly difficult to stay current with developments in their fields. LLMs excel at processing and summarizing large amounts of text, making them valuable tools for literature reviews, research synthesis, and knowledge discovery [8].
These models can quickly analyze research papers, extract key findings, identify trends across multiple studies, and even suggest connections between seemingly unrelated research areas. For academics, journalists, analysts, and other knowledge workers, this capability represents a significant productivity enhancement and can lead to new insights that might otherwise be missed.
Bridging Technical and Non-Technical Communication
One of the most valuable applications of LLMs is their ability to translate between technical and non-technical language. They can take complex technical concepts and explain them in accessible terms, or conversely, help non-technical users formulate their needs in ways that technical systems can understand [9].
This bridging capability is particularly valuable in software development, where LLMs can help generate code from natural language descriptions, explain existing code in plain English, and even help debug problems by analyzing error messages and suggesting solutions. This has made programming more accessible to non-programmers while also increasing the productivity of experienced developers.
The Technology Behind Large Language Models
Understanding how LLMs work requires exploring several key technological concepts. While the mathematics can be complex, the fundamental ideas are accessible to anyone willing to think through the process step by step.
The Tokenization Process: Converting Text to Numbers
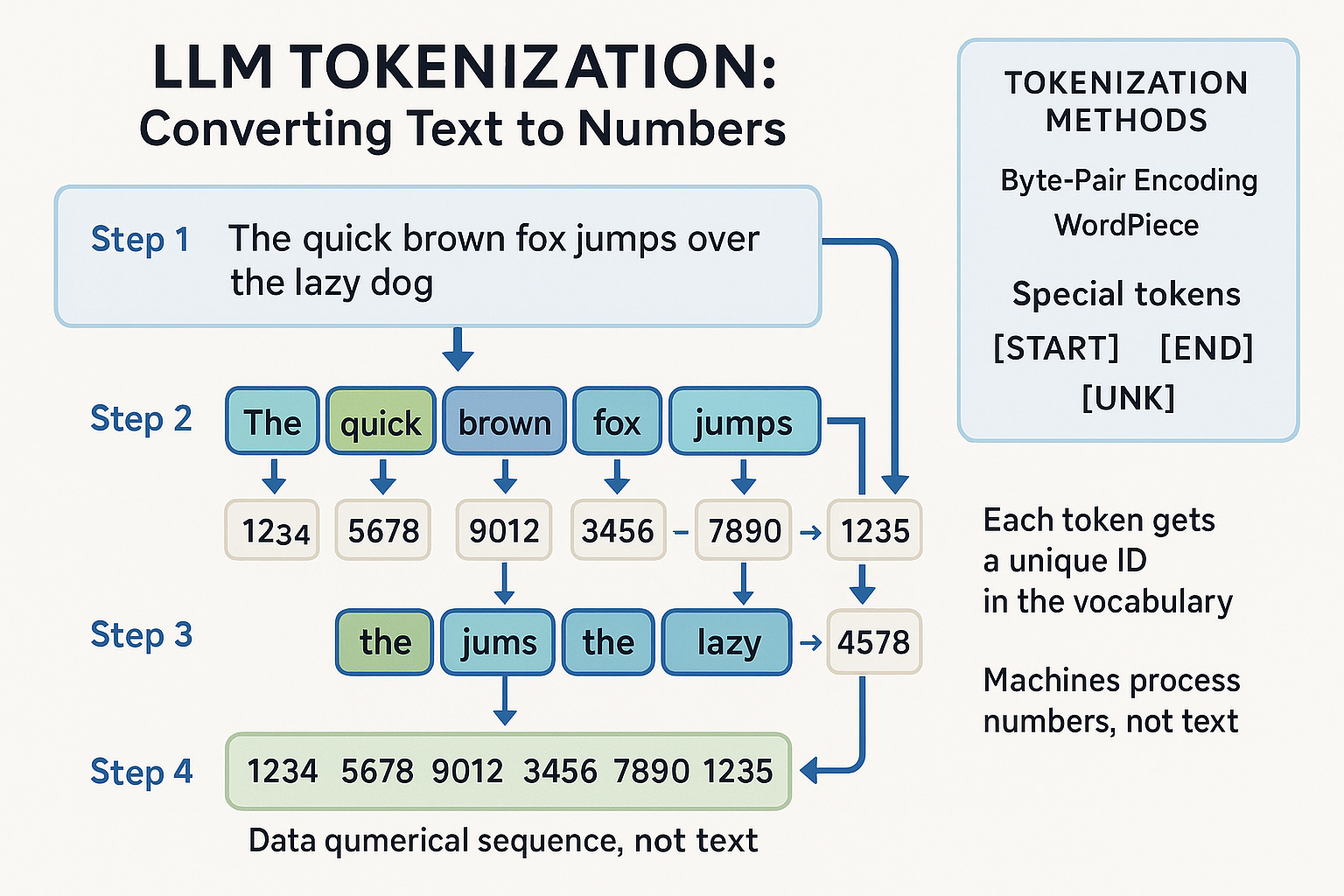
The first step in understanding LLMs is recognizing that computers process numbers, not text. Before any language processing can occur, text must be converted into numerical representations that machines can manipulate. This process is called tokenization [10].
Tokenization involves breaking text into smaller units called tokens, which might be words, parts of words, or even individual characters, depending on the specific approach used. Each token is then assigned a unique numerical identifier from a predefined vocabulary. For example, the sentence "The quick brown fox" might be tokenized into tokens like ["The", "quick", "brown", "fox"] and then converted to numbers like [1234, 5678, 9012, 3456].
Modern LLMs use sophisticated tokenization methods like Byte-Pair Encoding (BPE) or WordPiece, which can handle unknown words by breaking them down into smaller, known components. This approach allows models to process text they've never seen before by combining familiar pieces in new ways. Special tokens are also used to represent formatting, unknown words, and control characters that help the model understand the structure and context of the input.
The tokenization process also serves to compress the data and standardize input lengths. Since machine learning models typically require fixed-size inputs, shorter texts are "padded" with special tokens to match the length of longer texts. This preprocessing step is crucial for the efficient processing of language data at scale.
The Transformer Architecture: The Engine of Modern LLMs
The breakthrough that made modern LLMs possible was the development of the transformer architecture, introduced by Google researchers in their landmark 2017 paper "Attention Is All You Need" [11]. This architecture revolutionized natural language processing by introducing a more efficient and effective way to process sequential data like text.
The key innovation of transformers is the attention mechanism, which allows the model to focus on different parts of the input text when processing each word or token. Unlike previous approaches that processed text sequentially (one word at a time), transformers can process all words in a sentence simultaneously while still understanding the relationships between them.
Think of attention as a way for the model to ask, "When I'm trying to understand this word, which other words in the sentence are most relevant?" For example, when processing the sentence "The cat that was sleeping on the mat woke up," the attention mechanism helps the model understand that "woke up" refers to "the cat," not "the mat," even though "mat" is closer to "woke up" in the sentence.
Transformers consist of multiple layers, each containing attention mechanisms and neural network components. Modern LLMs like GPT-4 contain dozens of these layers, with each layer building upon the representations created by the previous layers. This deep architecture allows the models to capture increasingly complex patterns and relationships in the data.
The Training Process: Learning from Massive Datasets
The training of Large Language Models is a computationally intensive process that involves exposing the model to enormous amounts of text data and teaching it to predict patterns in that data. The primary training objective is surprisingly simple: given a sequence of words, predict the next word [12].
This process, called self-supervised learning, doesn't require human-labeled data. Instead, the model learns by trying to predict the next word in millions of sentences, gradually developing an understanding of grammar, semantics, facts about the world, and even reasoning patterns. It's like giving someone millions of books with the last word of each sentence covered up and asking them to guess what comes next.
The training datasets for modern LLMs are truly massive, often containing hundreds of billions of words from diverse sources including books, websites, academic papers, news articles, and reference materials. GPT-3, for example, was trained on approximately 45 terabytes of text data, representing a significant portion of the publicly available text on the internet [13].
The computational requirements for training these models are staggering. Training GPT-3 required thousands of high-end graphics processing units (GPUs) running for weeks, at an estimated cost of several million dollars. More recent models like GPT-4 and Google's PaLM required even more computational resources, with training costs reaching tens of millions of dollars [14].
Fine-tuning and Alignment: Making Models Helpful and Safe
While the initial training process teaches models to predict text patterns, additional steps are needed to make them useful and safe for real-world applications. This involves several techniques collectively known as fine-tuning and alignment [15].
Instruction fine-tuning teaches models to follow human instructions by training them on examples of instructions paired with appropriate responses. This process helps transform a model that simply predicts the next word into one that can answer questions, follow commands, and engage in helpful conversations.
Reinforcement Learning from Human Feedback (RLHF) is another crucial technique that involves training a reward model to predict which responses humans prefer, then using reinforcement learning to optimize the language model to generate responses that score highly according to this reward model [16]. This process helps ensure that models produce helpful, harmless, and honest responses rather than simply mimicking patterns from their training data.
These alignment techniques are crucial for making LLMs safe and useful in real-world applications. Without proper alignment, models might generate harmful content, provide misleading information, or fail to follow user instructions effectively.
The Advantages of Large Language Models

The rapid adoption of Large Language Models across industries and applications reflects their significant advantages over previous approaches to natural language processing and artificial intelligence more broadly.
Unprecedented Versatility and Generalization
Perhaps the most remarkable advantage of LLMs is their versatility. Unlike traditional AI systems that were designed for specific tasks, a single LLM can perform a wide variety of language-related tasks without task-specific training. This generalization capability means that the same model that can write poetry can also translate languages, summarize documents, answer questions, generate code, and engage in creative problem-solving [17].
This versatility stems from the models' ability to learn general patterns of language and reasoning during their training process. Rather than learning narrow, task-specific skills, LLMs develop broad capabilities that can be applied to new situations and challenges. This represents a fundamental shift in AI development, moving from specialized tools to general-purpose language understanding systems.
The practical implications of this versatility are enormous. Organizations can deploy a single LLM-based system to handle multiple use cases, reducing the complexity and cost of maintaining separate specialized systems. Developers can build applications that leverage the full range of language capabilities without needing expertise in multiple AI domains.
Human-like Text Generation and Understanding
LLMs have achieved a level of text generation quality that often makes it difficult to distinguish between human and machine-generated content. This capability extends beyond simple text generation to include understanding context, maintaining consistency across long conversations, adapting writing style to different audiences, and even demonstrating creativity and humor [18].
The quality of text generation has practical implications across numerous applications. Marketing teams can generate compelling copy, technical writers can produce documentation, educators can create learning materials, and content creators can develop engaging articles and stories. The ability to maintain context and consistency makes LLMs particularly valuable for long-form content creation and complex conversational applications.
This human-like capability also extends to understanding and interpreting text. LLMs can analyze sentiment, extract key information, identify themes and patterns, and even understand implicit meanings and cultural references. This deep understanding enables sophisticated applications in content analysis, research, and knowledge extraction.
Rapid Processing and Scalability
Once trained, LLMs can process and generate text at remarkable speeds, handling thousands of requests simultaneously. This scalability makes them practical for large-scale applications serving millions of users. Unlike human experts who can only handle one conversation or task at a time, LLMs can engage with unlimited numbers of users simultaneously while maintaining consistent quality [19].
This rapid processing capability is particularly valuable for real-time applications like customer service, where immediate responses are crucial for user satisfaction. LLMs can provide instant, contextually appropriate responses to customer queries, reducing wait times and improving the overall customer experience.
The scalability also extends to handling large volumes of text processing tasks. LLMs can analyze thousands of documents, generate hundreds of articles, or process massive datasets in the time it would take human experts to handle a fraction of the workload.
Multilingual Capabilities and Global Accessibility
Modern LLMs demonstrate impressive multilingual capabilities, able to understand and generate text in dozens of languages. This global reach makes them valuable tools for international communication, cross-cultural understanding, and breaking down language barriers in digital applications [20].
The multilingual capabilities extend beyond simple translation to include cultural adaptation, understanding of regional variations in language use, and the ability to maintain context across language switches within the same conversation. This makes LLMs particularly valuable for global businesses and organizations serving diverse, multilingual audiences.
These capabilities also contribute to digital accessibility, helping to make information and services available to speakers of languages that have traditionally been underserved by technology. While challenges remain in ensuring equal quality across all languages, LLMs represent a significant step toward more inclusive global communication technologies.
Cost-Effective Automation of Knowledge Work
LLMs enable the automation of many knowledge work tasks that previously required human expertise. This automation can significantly reduce costs while maintaining or even improving quality and consistency. Tasks like content creation, document analysis, customer support, and research assistance can be handled by LLMs at a fraction of the cost of human experts [21].
The cost-effectiveness extends beyond simple labor substitution to include the ability to handle tasks that might not have been economically viable with human resources. Small businesses can access capabilities that were previously available only to large organizations with substantial budgets for specialized expertise.
This democratization of advanced language capabilities has the potential to level the playing field across organizations of different sizes and resources, enabling innovation and efficiency improvements across the economy.
Accessibility and Assistive Technology Applications
LLMs have significant potential as assistive technologies for individuals with disabilities. They can convert text to speech, provide detailed descriptions of visual content, simplify complex language for individuals with cognitive disabilities, and serve as communication aids for those with speech or language impairments [22].
The conversational nature of LLM interfaces makes them particularly accessible to users who may struggle with traditional computer interfaces. Voice-based interactions with LLMs can provide access to information and services for individuals with visual impairments or motor disabilities that make traditional computing challenging.
These accessibility applications represent one of the most socially beneficial uses of LLM technology, helping to create more inclusive digital environments and expanding access to information and services for underserved populations.
The Challenges and Limitations of Large Language Models
While Large Language Models offer remarkable capabilities, they also present significant challenges and limitations that must be understood and addressed for responsible deployment and use.
Algorithmic Bias and Fairness Concerns
One of the most serious challenges facing LLMs is their tendency to perpetuate and amplify biases present in their training data. Since these models learn from vast amounts of text created by humans, they inevitably absorb the biases, stereotypes, and prejudices reflected in that content [23].
These biases can manifest in various ways. LLMs may associate certain professions with specific genders, exhibit racial or ethnic stereotypes, show political biases, or demonstrate cultural prejudices. For example, when asked to complete sentences about different professions, LLMs might consistently associate nursing with women and engineering with men, reflecting historical biases in their training data rather than current reality or desired equality.
The impact of these biases extends beyond individual interactions to systemic effects when LLMs are deployed at scale. Biased outputs in hiring tools, educational applications, or content generation systems can perpetuate discrimination and inequality. Addressing these biases requires ongoing research, careful dataset curation, and the development of techniques to detect and mitigate unfair outputs.
Selection bias is another related challenge, where LLMs may consistently favor certain types of responses or options regardless of context. This can undermine the reliability of LLMs in decision-making applications and highlights the need for careful evaluation and testing across diverse scenarios and populations.
Hallucinations and Factual Accuracy
Perhaps one of the most concerning limitations of current LLMs is their tendency to generate plausible-sounding but factually incorrect information, a phenomenon known as hallucination [24]. LLMs can confidently present false facts, create non-existent citations, or provide misleading information while maintaining a convincing and authoritative tone.
This challenge stems from the fundamental nature of how LLMs work. They generate text based on patterns learned from training data, not from a verified knowledge base or real-time access to factual information. When faced with questions about topics they haven't seen frequently in training data, or when asked for specific facts they don't "know," LLMs may generate responses that sound reasonable but are entirely fabricated.
The hallucination problem is particularly dangerous because the generated misinformation can be highly convincing. LLMs can create detailed, internally consistent false narratives complete with fake statistics, non-existent studies, and fabricated expert quotes. This makes it challenging for users to identify when they're receiving inaccurate information, especially in domains where they lack expertise.
Addressing hallucinations requires multiple approaches, including better training techniques, integration with verified knowledge sources, uncertainty quantification methods that help models express when they're unsure, and user education about the limitations of LLM-generated content.
Security Vulnerabilities and Prompt Injection
LLMs face unique security challenges that don't exist in traditional software systems. Prompt injection attacks involve crafting inputs that manipulate the model into ignoring its instructions or safety guidelines [25]. These attacks can cause models to generate harmful content, reveal sensitive information, or behave in unintended ways.
For example, an attacker might embed hidden instructions in seemingly innocent text that cause an LLM to ignore its safety guidelines and generate inappropriate content. More sophisticated attacks might involve creating "sleeper agents" – models that behave normally under most conditions but activate malicious behaviors when triggered by specific inputs or conditions.
The challenge of securing LLMs is compounded by their complexity and the difficulty of predicting all possible inputs and outputs. Traditional software security relies on controlling access to specific functions and data, but LLMs process natural language inputs that can be crafted in countless ways to achieve malicious goals.
Research into LLM security is ongoing, with approaches including better input filtering, output monitoring, adversarial training to make models more robust to attacks, and the development of formal verification methods for AI systems.
Privacy and Data Protection Concerns
The training process for LLMs raises significant privacy concerns. These models are trained on vast datasets that may include personal information, private communications, copyrighted content, and other sensitive data scraped from the internet without explicit consent [26].
There are documented cases of LLMs reproducing personal information, private communications, and copyrighted content from their training data when prompted in specific ways. This raises questions about data ownership, consent, and the right to privacy in the age of large-scale AI training.
The memorization problem, where LLMs can reproduce exact passages from their training data, is particularly concerning from a privacy perspective. Studies have shown that LLMs can be prompted to output personal information, private communications, and other sensitive content that was included in their training datasets.
Addressing these privacy concerns requires careful consideration of data collection practices, the development of techniques to remove or protect sensitive information in training datasets, and legal frameworks that balance innovation with privacy rights.
Environmental Impact and Energy Consumption
The computational requirements for training and running LLMs have significant environmental implications. Training large models requires massive amounts of electricity, often generated by non-renewable sources, contributing to greenhouse gas emissions and climate change [27].
The energy demands extend beyond training to inference – the process of running trained models to generate responses. As LLMs become more widely deployed, the cumulative energy consumption for serving billions of requests daily becomes substantial. Data centers supporting LLM applications require significant electricity for both computation and cooling.
Some estimates suggest that training a single large language model can consume as much electricity as hundreds of homes use in a year. As models become larger and more capable, these energy requirements continue to grow, raising questions about the sustainability of current approaches to AI development.
Addressing the environmental impact requires research into more efficient training methods, the use of renewable energy sources for AI computation, and the development of smaller, more efficient models that can achieve similar capabilities with lower computational requirements.
Economic Disruption and Job Displacement
The capabilities of LLMs raise concerns about potential job displacement across various industries. As these models become capable of performing tasks traditionally done by human knowledge workers, there are legitimate concerns about unemployment and economic disruption [28].
Goldman Sachs research suggests that generative AI could potentially automate tasks equivalent to 300 million full-time jobs globally, with particular impact on white-collar professions that involve writing, analysis, and communication [29]. While new jobs may be created in AI development and deployment, the transition period could be challenging for affected workers.
The economic impact extends beyond individual job displacement to broader questions about the distribution of benefits from AI productivity gains. If LLMs enable significant productivity improvements but the benefits accrue primarily to technology companies and their shareholders, this could exacerbate economic inequality.
Addressing these economic challenges requires proactive policy responses, including retraining programs, social safety nets, and consideration of how to ensure that the benefits of AI advancement are broadly shared across society.
Cognitive and Social Impact
The widespread adoption of LLMs may have subtle but significant impacts on human cognitive abilities and social interactions. There are concerns that over-reliance on AI for writing, analysis, and problem-solving could lead to atrophy of these skills in humans [30].
Educational institutions face particular challenges in adapting to a world where students have access to AI systems capable of completing assignments, writing essays, and solving problems. This raises questions about how to maintain academic integrity while also preparing students for a future where AI collaboration will be commonplace.
The social impact of LLMs extends to questions about authenticity in communication and creative work. As AI-generated content becomes more prevalent and harder to distinguish from human-created content, this may affect trust, attribution, and the value placed on human creativity and expertise.
Current Applications and Real-World Impact
The theoretical capabilities of Large Language Models have translated into practical applications across numerous industries and use cases, demonstrating their real-world value while also highlighting areas where challenges remain.
Customer Service and Support Revolution
The customer service industry has been one of the earliest and most successful adopters of LLM technology. Companies across sectors are deploying LLM-powered chatbots and virtual assistants that can handle complex customer inquiries with unprecedented sophistication [31].
Unlike traditional rule-based chatbots that could only handle predefined scenarios, LLM-powered systems can understand context, handle follow-up questions, and provide personalized responses based on customer history and preferences. They can troubleshoot technical problems, process returns and exchanges, provide product recommendations, and even handle complaints with appropriate empathy and understanding.
Major companies like IBM with their Watson Assistant, Microsoft with their Copilot integration, and numerous startups have developed LLM-powered customer service solutions that are being deployed at scale. These systems can handle thousands of simultaneous conversations while maintaining consistent quality and availability 24/7.
The impact extends beyond cost savings to improved customer satisfaction. LLM-powered systems can provide immediate responses, remember conversation context, and escalate complex issues to human agents when appropriate. This hybrid approach combines the efficiency of AI with the nuanced understanding of human agents.
Content Creation and Marketing Transformation
The content creation industry has been fundamentally transformed by LLMs. Marketing teams, content creators, and publishers are using these tools to generate blog posts, social media content, email campaigns, product descriptions, and advertising copy at unprecedented scale and speed [32].
LLMs excel at adapting content for different audiences, platforms, and purposes. A single piece of source material can be transformed into multiple formats – from detailed blog posts to concise social media updates, from technical documentation to consumer-friendly explanations. This versatility has made content creation more efficient and accessible to organizations of all sizes.
The creative industries are also exploring LLM applications, with writers using AI as collaborative partners for brainstorming, editing, and overcoming writer's block. Publishers are experimenting with AI-assisted content generation for news summaries, sports reporting, and other routine content types.
However, this transformation also raises questions about authenticity, quality control, and the value of human creativity. Many organizations are developing guidelines for AI-assisted content creation that maintain editorial standards while leveraging the efficiency benefits of LLM technology.
Education and Learning Enhancement
Educational institutions and EdTech companies are exploring numerous applications of LLMs to enhance learning experiences. These range from personalized tutoring systems that can adapt to individual learning styles to automated essay grading and feedback systems [33].
LLM-powered tutoring systems can provide 24/7 availability, infinite patience, and personalized explanations tailored to each student's level of understanding. They can break down complex concepts, provide additional examples, and adapt their teaching approach based on student responses and progress.
Language learning applications have been particularly successful, with LLMs providing conversational practice partners that can engage in natural dialogue, correct grammar and pronunciation, and provide cultural context for language use. These systems can simulate conversations with native speakers and provide immediate feedback on language use.
Research assistance is another growing application, with LLMs helping students and researchers find relevant sources, summarize academic papers, and identify connections between different research areas. However, educational institutions are also grappling with challenges around academic integrity and ensuring that students develop critical thinking skills rather than simply relying on AI-generated answers.
Healthcare and Medical Applications
The healthcare industry is cautiously exploring LLM applications, recognizing both the potential benefits and the critical importance of accuracy and safety in medical contexts [34]. Applications include medical documentation, patient communication, research assistance, and clinical decision support.
LLMs can help healthcare providers generate clinical notes, summarize patient histories, and translate medical information into language that patients can understand. They can assist with medical coding, insurance documentation, and other administrative tasks that consume significant physician time.
Research applications include literature review assistance, hypothesis generation, and analysis of clinical trial data. LLMs can help researchers stay current with the rapidly expanding medical literature and identify potential connections between different research areas.
However, medical applications require exceptional accuracy and safety standards. The potential consequences of AI-generated medical misinformation are severe, leading to careful validation processes and human oversight requirements for any medical AI applications.
Software Development and Programming
The software development industry has embraced LLMs as powerful coding assistants. Tools like GitHub Copilot, powered by OpenAI's Codex model, can generate code from natural language descriptions, complete partially written functions, and even debug existing code [35].
These tools have significantly increased developer productivity by handling routine coding tasks, generating boilerplate code, and providing suggestions for complex algorithms. They can work across multiple programming languages and adapt to different coding styles and conventions.
LLMs are also being used for code documentation, test generation, and code review assistance. They can explain existing code in natural language, generate comprehensive documentation, and identify potential bugs or security vulnerabilities.
The impact on software development education has been particularly notable, with LLMs making programming more accessible to beginners by providing natural language interfaces to coding concepts and immediate assistance with syntax and logic errors.
Legal and Professional Services
Law firms and legal departments are exploring LLM applications for document review, contract analysis, legal research, and brief writing [36]. These applications can significantly reduce the time required for routine legal tasks while maintaining high accuracy standards.
LLMs can analyze contracts for specific clauses, identify potential risks, and suggest standard language for common legal documents. They can assist with legal research by quickly identifying relevant cases, statutes, and regulations, and summarizing key legal principles.
Document review, traditionally one of the most time-intensive aspects of legal work, can be accelerated through LLM-powered systems that can quickly identify relevant documents, extract key information, and flag potential issues for human review.
However, legal applications require exceptional accuracy and accountability standards. The legal profession is developing guidelines for AI use that ensure proper oversight, validation, and ethical compliance while leveraging the efficiency benefits of LLM technology.
The Future of Large Language Models
As we look toward the future of Large Language Models, several trends and developments are shaping the trajectory of this transformative technology.
Multimodal Integration and Expanded Capabilities
The next generation of LLMs is moving beyond text-only processing to incorporate multiple modalities including images, audio, and video. These multimodal models can understand and generate content across different media types, opening up new applications and use cases [37].
Current examples include models that can analyze images and generate descriptive text, create images from text descriptions, or engage in conversations about visual content. Future developments may include models that can process and generate video content, understand audio in context, and seamlessly integrate information across multiple sensory modalities.
This multimodal capability will enable more natural and comprehensive AI assistants that can understand the full context of human communication and interaction. Applications might include AI systems that can analyze medical images while discussing symptoms, educational tools that can create visual explanations of complex concepts, or creative assistants that can work across text, image, and audio domains.
Improved Efficiency and Accessibility
Research into more efficient LLM architectures and training methods is making these powerful capabilities more accessible to smaller organizations and individual developers. Techniques like model compression, knowledge distillation, and efficient fine-tuning are reducing the computational requirements for deploying and customizing LLMs [38].
Open-source models like Meta's LLaMA, Mistral AI's models, and various community-developed alternatives are democratizing access to LLM technology. These developments are enabling innovation beyond the largest technology companies and fostering a more diverse ecosystem of AI applications and research.
Edge deployment of LLMs is another important trend, with researchers developing techniques to run capable language models on smartphones, laptops, and other consumer devices. This local processing capability addresses privacy concerns while enabling AI assistance even without internet connectivity.
Enhanced Safety and Alignment
Ongoing research into AI safety and alignment is developing better techniques for ensuring that LLMs behave in helpful, harmless, and honest ways. Constitutional AI, improved RLHF methods, and formal verification techniques are making LLMs more reliable and trustworthy [39].
Advances in interpretability research are helping us better understand how LLMs make decisions and generate responses. This understanding is crucial for identifying potential biases, predicting failure modes, and ensuring that AI systems behave as intended across diverse scenarios and applications.
Regulatory frameworks and industry standards are also evolving to provide guidelines for responsible LLM development and deployment. These frameworks aim to balance innovation with safety, privacy, and ethical considerations.
Specialized and Domain-Specific Models
While general-purpose LLMs have demonstrated remarkable versatility, there's growing interest in developing specialized models optimized for specific domains or applications. These domain-specific models can achieve better performance and efficiency by focusing on particular areas of expertise [40].
Examples include models specialized for scientific research, legal analysis, medical applications, or specific industries. These specialized models can incorporate domain-specific knowledge, terminology, and reasoning patterns while maintaining the general language understanding capabilities of broader LLMs.
The development of specialized models also addresses some of the challenges associated with general-purpose systems, including reducing hallucinations in specific domains, improving factual accuracy, and ensuring appropriate behavior for high-stakes applications.
Integration with External Knowledge and Tools
Future LLMs will likely be more tightly integrated with external knowledge sources, databases, and computational tools. This integration can address current limitations around factual accuracy and real-time information access [41].
Retrieval-augmented generation (RAG) systems that combine LLMs with searchable knowledge bases are already showing promise for improving factual accuracy and enabling access to current information. Future developments may include more sophisticated integration with databases, APIs, and computational tools.
These integrated systems could enable LLMs to perform complex multi-step tasks that require both language understanding and access to external resources. Applications might include AI research assistants that can access and analyze current literature, business intelligence systems that can query databases and generate reports, or educational tools that can access current information and create up-to-date learning materials.
Conclusion: Navigating the LLM Revolution
Large Language Models represent one of the most significant technological developments of our time, with implications that extend far beyond the realm of artificial intelligence research. As we've explored throughout this comprehensive guide, LLMs offer remarkable capabilities that are already transforming industries, enhancing human productivity, and opening new possibilities for human-computer interaction.
The journey from the early statistical language models of the 1990s to today's sophisticated transformer-based systems like GPT-4, Gemini, and Claude represents decades of research, innovation, and computational advancement. The breakthrough of the transformer architecture, combined with massive datasets and computational resources, has enabled AI systems that can understand and generate human language with unprecedented fluency and versatility.
The advantages of LLMs are clear and compelling. Their versatility allows single systems to handle multiple language-related tasks, from translation and summarization to creative writing and code generation. Their human-like text generation capabilities have made AI assistance more natural and accessible. Their scalability enables deployment across millions of users simultaneously, while their multilingual capabilities are breaking down language barriers and democratizing access to information and services.
Yet, as we've also seen, these powerful capabilities come with significant challenges that must be addressed thoughtfully and proactively. Algorithmic bias, hallucinations, security vulnerabilities, privacy concerns, environmental impact, and potential economic disruption are not merely technical problems to be solved, but complex societal challenges that require collaboration between technologists, policymakers, ethicists, and the broader public.
The current applications of LLMs across customer service, content creation, education, healthcare, software development, and professional services demonstrate both the transformative potential and the practical considerations involved in deploying these systems responsibly. Success stories highlight the efficiency gains and new capabilities that LLMs enable, while ongoing challenges remind us of the importance of human oversight, validation, and ethical consideration.
Looking toward the future, the trajectory of LLM development points toward even more capable, efficient, and integrated systems. Multimodal capabilities will enable AI that can understand and generate content across text, images, audio, and video. Improved efficiency will make these capabilities more accessible to smaller organizations and individual users. Enhanced safety and alignment techniques will make LLMs more reliable and trustworthy. Specialized models will provide domain-specific expertise while maintaining general language understanding.
For individuals and organizations seeking to understand and leverage LLM technology, several key principles emerge from our exploration:
Stay Informed and Engaged: The field of LLMs is evolving rapidly, with new capabilities, applications, and challenges emerging regularly. Staying informed about developments, best practices, and emerging guidelines is crucial for effective and responsible use.
Understand Limitations: While LLMs are remarkably capable, understanding their limitations is essential for appropriate application. Recognizing when human oversight is necessary, when outputs should be verified, and when alternative approaches might be more suitable is crucial for successful implementation.
Prioritize Ethics and Responsibility: The power of LLMs comes with responsibility. Consider the potential impacts of AI applications on users, society, and the environment. Implement appropriate safeguards, validation processes, and ethical guidelines.
Embrace Human-AI Collaboration: The most successful applications of LLMs typically involve collaboration between human expertise and AI capabilities rather than simple replacement of human workers. Focus on how AI can augment and enhance human capabilities rather than simply automating tasks.
Prepare for Continued Change: The LLM revolution is still in its early stages. Organizations and individuals should prepare for continued rapid change, new capabilities, and evolving best practices. Building adaptable systems and maintaining learning mindsets will be crucial for long-term success.
As we stand at this inflection point in the development of artificial intelligence, Large Language Models represent both tremendous opportunity and significant responsibility. Their ability to understand and generate human language opens possibilities we're only beginning to explore, from more natural human-computer interfaces to AI assistants that can truly understand and help with complex tasks.
The choices we make today about how to develop, deploy, and govern these systems will shape their impact on society for years to come. By approaching LLM technology with both enthusiasm for its potential and respect for its challenges, we can work toward a future where artificial intelligence enhances human capabilities, promotes equity and accessibility, and contributes to solving some of our most pressing global challenges.
The conversation about Large Language Models is far from over. As these systems become more capable and more widely deployed, ongoing dialogue between technologists, policymakers, ethicists, and the public will be essential for ensuring that the benefits of this transformative technology are realized while minimizing potential harms.
Whether you're a business leader considering AI adoption, a developer building LLM-powered applications, an educator adapting to AI-enhanced learning environments, or simply a curious individual trying to understand the technology shaping our world, your engagement with and understanding of Large Language Models will play a role in determining how this powerful technology evolves and impacts society.
The future of Large Language Models is not predetermined – it will be shaped by the choices, innovations, and values of the people who develop, deploy, and use these systems. By staying informed, thinking critically, and engaging thoughtfully with this technology, we can all contribute to ensuring that the LLM revolution benefits humanity as a whole.
References
[1] IBM. "What Are Large Language Models (LLMs)?" IBM Think. https://www.ibm.com/think/topics/large-language-models
[2] Wikipedia. "Large language model." https://en.wikipedia.org/wiki/Large_language_model
[3] IBM. "Foundation Models and Large Language Models." IBM Research. https://www.ibm.com/think/topics/large-language-models
[4] Wikipedia. "Large language model - History." https://en.wikipedia.org/wiki/Large_language_model#History
[5] IBM. "LLM Use Cases - Language Translation." https://www.ibm.com/think/topics/large-language-models
[6] IBM. "LLM Use Cases - Content Generation." https://www.ibm.com/think/topics/large-language-models
[7] IBM. "LLM Use Cases - AI Assistants." https://www.ibm.com/think/topics/large-language-models
[8] IBM. "LLM Use Cases - Research and Academia." https://www.ibm.com/think/topics/large-language-models
[9] IBM. "LLM Use Cases - Code Generation." https://www.ibm.com/think/topics/large-language-models
[10] Wikipedia. "Large language model - Dataset preprocessing - Tokenization." https://en.wikipedia.org/wiki/Large_language_model#Tokenization
[11] Wikipedia. "Large language model - History - Transformer Era." https://en.wikipedia.org/wiki/Large_language_model#History
[12] Wikipedia. "Large language model - Training." https://en.wikipedia.org/wiki/Large_language_model#Training
[13] Wikipedia. "Large language model - Training - Cost." https://en.wikipedia.org/wiki/Large_language_model#Cost
[14] Wikipedia. "Large language model - Training - Cost." https://en.wikipedia.org/wiki/Large_language_model#Cost
[15] Wikipedia. "Large language model - Training - Fine-tuning." https://en.wikipedia.org/wiki/Large_language_model#Fine-tuning
[16] Wikipedia. "Large language model - Training - Fine-tuning - RLHF." https://en.wikipedia.org/wiki/Large_language_model#Fine-tuning
[17] IBM. "What Are Large Language Models - Capabilities." https://www.ibm.com/think/topics/large-language-models
[18] IBM. "LLM Capabilities - Text Generation." https://www.ibm.com/think/topics/large-language-models
[19] IBM. "LLM Advantages - Scalability." https://www.ibm.com/think/topics/large-language-models
[20] IBM. "LLM Use Cases - Language Translation." https://www.ibm.com/think/topics/large-language-models
[21] Wikipedia. "Large language model - Ethical issues - Economic Impact." https://en.wikipedia.org/wiki/Large_language_model#Ethical_issues
[22] IBM. "LLM Use Cases - Accessibility." https://www.ibm.com/think/topics/large-language-models
[23] Wikipedia. "Large language model - Ethical issues - Algorithmic bias." https://en.wikipedia.org/wiki/Large_language_model#Algorithmic_bias
[24] IBM. "LLM Challenges - Hallucinations." https://www.ibm.com/think/topics/large-language-models
[25] Wikipedia. "Large language model - Ethical issues - Security - Prompt injection." https://en.wikipedia.org/wiki/Large_language_model#Prompt_injection
[26] Wikipedia. "Large language model - Ethical issues - Memorization and copyright." https://en.wikipedia.org/wiki/Large_language_model#Memorization_and_copyright
[27] Wikipedia. "Large language model - Ethical issues - Energy demands." https://en.wikipedia.org/wiki/Large_language_model#Energy_demands
[28] Wikipedia. "Large language model - Ethical issues - Economic Impact." https://en.wikipedia.org/wiki/Large_language_model#Ethical_issues
[29] Wikipedia. "Large language model - Ethical issues - Economic Impact." https://en.wikipedia.org/wiki/Large_language_model#Ethical_issues
[30] Wikipedia. "Large language model - Ethical issues - Cognitive impact." https://en.wikipedia.org/wiki/Large_language_model#Cognitive_impact
[31] IBM. "LLM Use Cases - Customer Service." https://www.ibm.com/think/topics/large-language-models
[32] IBM. "LLM Use Cases - Content Generation." https://www.ibm.com/think/topics/large-language-models
[33] Wikipedia. "Large language model - Applications - Education." https://en.wikipedia.org/wiki/Large_language_model
[34] Wikipedia. "Large language model - Applications - Healthcare." https://en.wikipedia.org/wiki/Large_language_model
[35] Wikipedia. "Large language model - Applications - Software Development." https://en.wikipedia.org/wiki/Large_language_model
[36] Wikipedia. "Large language model - Applications - Legal Services." https://en.wikipedia.org/wiki/Large_language_model
[37] Wikipedia. "Large language model - History - Multimodal Models." https://en.wikipedia.org/wiki/Large_language_model#History
[38] Wikipedia. "Large language model - Future Developments." https://en.wikipedia.org/wiki/Large_language_model
[39] Wikipedia. "Large language model - Training - Fine-tuning - Constitutional AI." https://en.wikipedia.org/wiki/Large_language_model#Fine-tuning
[40] Wikipedia. "Large language model - Specialized Models." https://en.wikipedia.org/wiki/Large_language_model
[41] Wikipedia. "Large language model - Extensibility." https://en.wikipedia.org/wiki/Large_language_model#Extensibility
This comprehensive guide to Large Language Models was written to provide both technical and non-technical readers with a thorough understanding of this transformative technology. As the field continues to evolve rapidly, staying informed about new developments, best practices, and emerging challenges will be crucial for anyone working with or affected by LLM technology.